

Hi Folks!
In today’s blog I will be introducing you to a new open source distributed Sql Query Engine – Presto. It is designed for running SQL queries over Big Data( petabytes of Data). It was designed by the people at Facebook.
Introduction
Quoting it’s formal definition “Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.”
The motive behind the inception of Presto was to enable interactive analytics and approaches the speed of commercial data warehouses with the power to scala size of organisations matching Facebook.
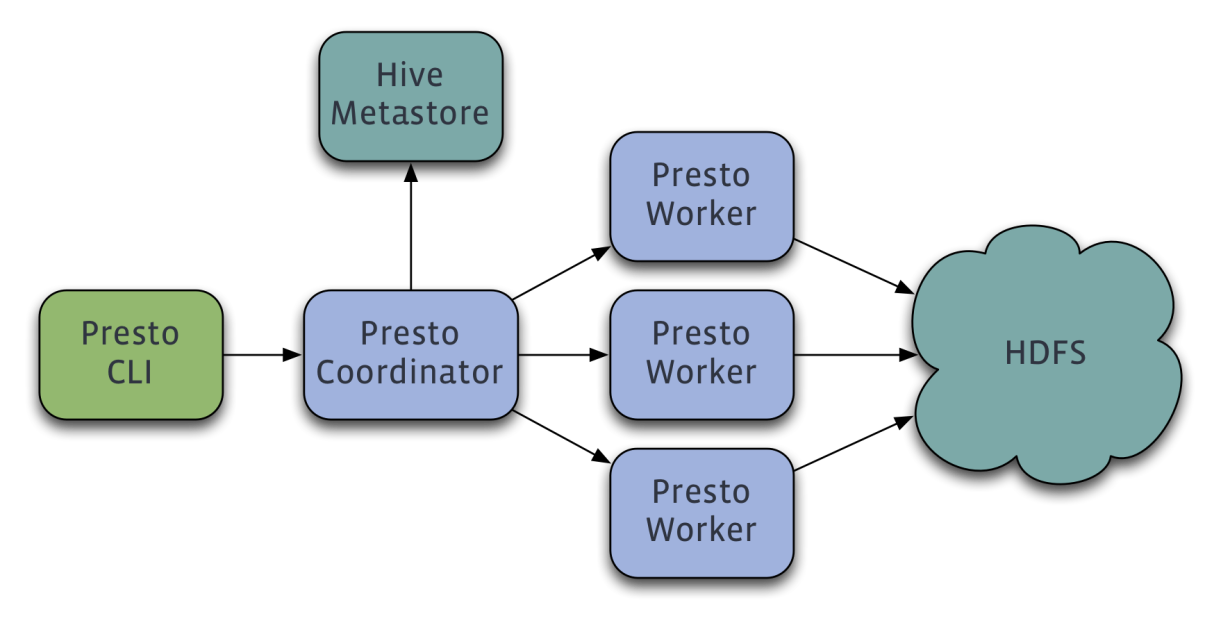
Presto is a distributed query engine that runs on a cluster of machines. A full setup includes a coordinator and multiple workers. Queries are submitted from a client such as the Presto CLI to the coordinator. The coordinator parses, analyses and plans the query execution, then distributes the processing to the workers.
Idea behind inception of Presto
Working with terabytes or petabytes of data, one is likely to use tools that interact with Hadoop and HDFS. Presto was designed as an alternative to tools that query HDFS using pipelines of MapReduce jobs such as Hive or Pig, but Presto is not limited to accessing HDFS. Presto can be and has been extended to operate over different kinds of data sources including traditional relational databases and other data sources such as Cassandra.
Capabilities of Presto
- Allow querying over data where it is residing like Hive, Cassandra, relational databases or even proprietary data stores.
- Allowing a single Presto query to combine data from multiple sources.
- Faster response time breaking the myth that “having fast analytics using an expensive commercial solution or using a slow “free” solution that requires excessive hardware.”
Credit ability
Facebook uses Presto daily to run more than 30,000 queries that in total scan over a petabyte each per day over several internal data stores, including their 300PB data warehouse.
Connectors in Presto
Presto supports pluggable connectors that provide data for queries. There are several pre- existent connectors, while presto provides ability to connect with custom connectors as well. It supports the following connectors :
- Hadoop / Hive
(Apache Hadoop 1.x, Apache Hadoop 2.x, Cloudera CDH 4,Cloudera CDH 5) - Cassandra
(Cassandra 2.x is required. This connector is completely independent of the Hive connector and only requires an existing Cassandra installation.) - TPC-H
(The connector dynamically generates data that can be used for experimenting with Presto)
Before we go further , while analyzing the tool for its features it becomes equally important to know what it is not capable of. This helps in determining its use cases and usability.
What Presto is Not
Presto is not a general-purpose relational database.
It is not a replacement for databases like MySQL, PostgreSQL or Oracle.
Presto is not designed to handle Online Transaction Processing (OLTP)
Competitors vs Presto
- Presto continue lead in BI-type queries and Spark leads performance-wise in large analytics queries. Presto scales better than Hive and Spark for concurrent dashboard queries. Production enterprise BI user-bases may be on the order of 100s or 1,000s of users. As such, support for concurrent query workloads is critical. Benchmarks show that Presto performed the best – that is, showed the least query degradation – as concurrent query workload increased and showed the best results in user concurrency testing.
- Another advantage of Presto over Spark and Impala is it Gets ready in minutes
- Presto works directly on files in s3 , requiring no ETL transformations.
In my next blog , I will discuss how to get started with Presto.
Happy Reading:)
References
- https://prestodb.io/docs/current/
- http://www.infoworld.com/article/3131058/analytics/big-data-face-off-spark-vs-impala-vs-hive-vs-presto.html
- http://www.atscale.com/press/new-business-intelligence-performance-benchmark-reveals-strong-innovation-among-open-source-projects/
- https://stackshare.io/stackups/impala-vs-spark-vs-presto

2 thoughts on “Getting Introduced with Presto3 min read”
Comments are closed.