

![]()
Heavy Data Load? Kafka Is Here For You.
In this blog, I am going to get into the details like:
- What is Kafka?
- Getting familiar with Kafka.
- Learning some basics in Kafka.
- Creating a general Single Broker Cluster.
So let’s get started.
1. What is Kafka?
In simple terms, KAFKA is a messaging system that is designed to be fast, scalable, and durable. It is an open source stream processing platform. Apache Kafka was originated at LinkedIn and later became an open-sourced Apache project in 2011, then First-class Apache project in 2012. Kafka is written in Scala and Java. It aims at providing High-throughput, low-latency platform for handling real-time data feeds.
2. Getting familiar with Kafka.
Apache describes Kafka as a Distributed Streaming Platform, that lets us:
- Publish and Subscribe to streams of records.
- Store streams of records in a fault-tolerant way.
- Process streams of records as they occur.
So the first question that comes to mind is why Kafka?
The answer is pretty simple and straightforward: “In Big Data, an enormous volume of data is used, But how are we going to collect this large volume of data and analyze that data?” To overcome this, we must need a messaging system. That is why we need KAFKA. The functionalities that it provides are well suited for our requirements, and thus we use Kafka for (1) Building real-time streaming data pipelines that can get us data between systems and applications, and (2) Building real-time streaming applications to react to the stream of data.
Next question that is of interest here is, what is a messaging system?
A Messaging System is a system that is used for transferring data from one application to another, so the applications can focus on data, and not on how to share it. Kafka is a distributed publish-subscribe messaging system. In the publish-subscribe system, messages are persisted in a topic. Message producers are called publishers and message consumers are called subscribers. Consumers can subscribe to one or more topic and consume all the messages in that topic(we will discuss these terminologies later in the post).
Now that we know what Kafka is, let’s check out its benefits.
a) Reliability: Kafka is distributed, partitioned, replicated and fault tolerance. Kafka replicates data and is able to support multiple subscribers. Additionally, it automatically balances consumers in the event of failure.
b) Scalability: Kafka is a distributed system that scales quickly and easily without incurring any downtime.
c) Durability: Kafka uses Distributed commit log
which means messages persists on disk as fast as possible providing intra-cluster replication, hence it is durable.
d) Performance: Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even when dealing with many terabytes of stored messages.
Now I think that we can move on to our next step that is Kafka Basics.
3. Learning some basics in Kafka.
Apache.org states that,
- Kafka runs as a cluster, on one or more servers.
- The Kafka cluster stores stream of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
Topics and Logs: A topic is a feed name or category to which records are published, topics in Kafka are always multi-subscriber; that is a topic can have zero, one, or many consumers that subscribe to the data written to it. For each topic Kafka cluster maintains a partition log that looks like this: 
Partition: A topic may have many partitions so that it can handle an arbitrary amount of data. In the above diagram the topic is configured into 3 partitions(partition{0,1,2}). Partition0 has 13, offsets Partition1 has 10 offsets and Partition2 has 13 offsets.
Partition Offset: Each partitioned message has a unique sequence id called “offset” as in partition1 the offset is marked from 0-9.
Replicas: Replicas are nothing but backups
of a partition. If the replication factor of the above topic is set to 4, then Kafka will create 4 identical replicas of each partition and place them in the cluster to make available for all its operations.Replicas are never used to read or write data. They are used to prevent data loss.
Brokers: Brokers are simple system responsible for maintaining the published data. Kafka brokers are stateless, so they use ZooKeeper for maintaining their cluster state. Each broker may have zero or more partitions per topic, for example: if there are 10 partitions on a topic and 10 brokers then each broker will have 1 partition, but if there are 10 partitions and 15 brokers then starting 10 brokers will have one partition each and the remaining 5 won’t have any partition for that particular topic however if partitions are 15 but brokers are 10 then brokers would be sharing one or more partitions among them, leading to unequal load distribution among the brokers(try to avoid this scenario).
Zookeeper: ZooKeeper is used for managing and coordinating Kafka broker. ZooKeeper service is mainly used to notify producer and consumer about the presence of any new broker in the Kafka system or failure of any broker in the Kafka system. ZooKeeper notifies the Producer and Consumer about the presence or failure of a broker based on which producer and consumer takes a decision and start coordinating their task with some other broker.
Cluster: Kafka having more than one broker is called Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data.
Kafka has 4 core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
Till now we have discussed the theoretical concepts to get ourselves familiar with Kafka and now we will be using some of these concepts in setting up of our Single Broker Cluster, So let’s get onto it 🙂
4.Creating a general Single Broker Cluster.
To create a general single broker what I am assuming is we are using ubuntu16.04, and we have java1.8 or later installed. If Java is not installed get it from here.
Step1: Downloading Kafka Zip file.
Download the Kafka 0.10.2.0 release from here and untar it using the following command on your terminal, and then move to the directory containing our extracted Kafka.
> tar -xzf kafka_2.11-0.10.2.0.tgz
Step2: Starting your Kafka Server.
Now that we have extracted our Kafka and moved to its parent directory we can start our Kafka Server by just typing the following on our terminal.
> sudo kafka_2.11-0.10.2.0/bin/kafka-server-start.sh kafka_2.11-0.10.2.0/config/server.properties
On successful startup we can see following logs on our screen:

If Kafka server doesn’t start it is possible that your Zookeeper instance is not running, ZooKeeper should be up as a Daemon process by default and we can check that by entering this in the command line:
netstat -ant | grep :2181
If ZooKeeper ain’t up we can set it up by:
sudo apt -get install zookeeperd
By Default ZooKeeper is bundled in Ubuntu’s default Repository and once installed it will start as a daemon process and run on port 2181.
Step3: Creating your own Topic(Producer).
Now that we have our Kafka and ZooKeeper instances up and running we should test them by creating a topic and then consume and produce data from that topic. We can do it by:
sudo kafka_2.11-0.10.2.0/bin/kafka-console-producer.sh –broker-list localhost:9092 –topic yourTopicName
here topic with name “yourTopicName” would be created as soon as we press the Enter key, also it would work as your producer and the cursor would wait at the command line for you to input some message as we can see in the below snapshot.

Step4: Creating The Consumer.
As we have our producer up and running we now need a consumer to consume the messages that our producer would have produced, this can be done by:
sudo kafka_2.11-0.10.2.0/bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic yourTopicName –from-beginning
This would fetch all our messages from the beginning that our producer has produced since it was up. We would get something like this:
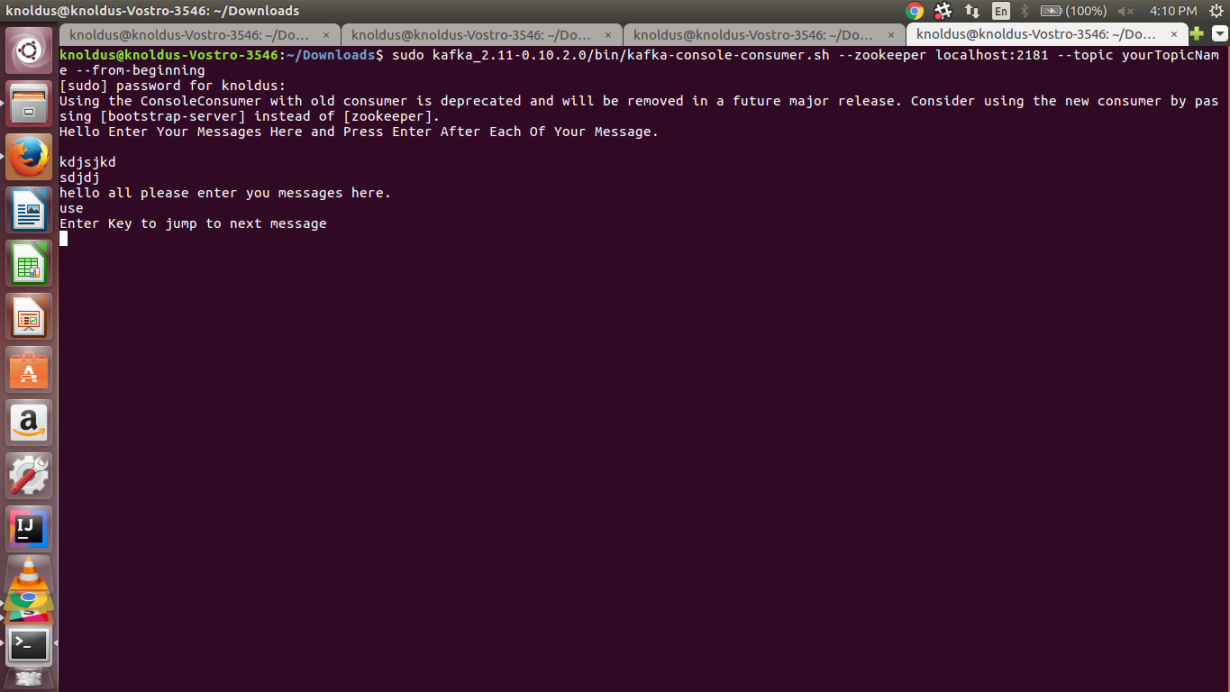
Now we have both our producer and consumer Kafka instances up and running.
Note: We can create multiple testing topics and then can produce and consume on these testing topics simultaneously.
Step5: Listing Topics.
As there is no upper bound to the number of topics that we can create in Kafka so it would be helpful if we could see the complete list of topics created. This can be done by:
sudo kafka_2.11-0.10.2.0/bin/kafka-topics.sh –list –zookeeper localhost:2181
after we press enter we can see a list of topics created by us as shown in the snapshot below:
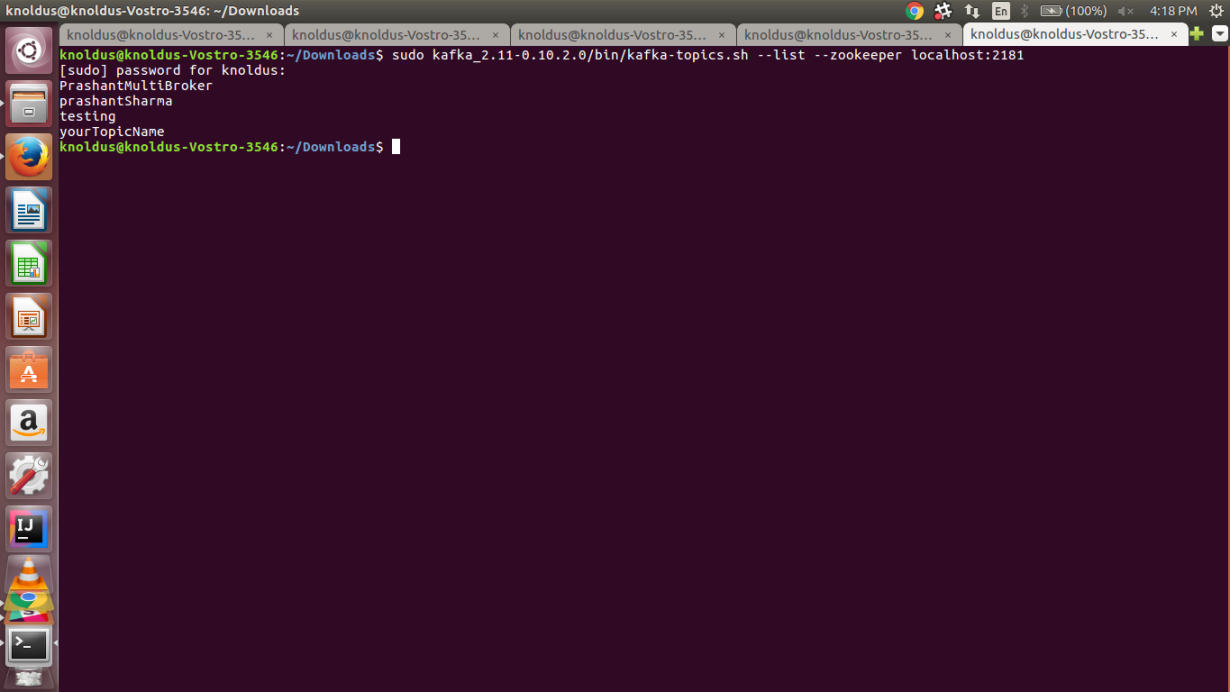
That is all we need to do for a Single Broker Cluster, next time I will be going deeper into Kafka(less Theory & more Practical 😛 ) and we’ll be looking at how to set up a Multi-Broker Cluster.
Till Then,
Happy Reading 🙂 🙂
References:
- https://kafka.apache.org/
- https://www.tutorialspoint.com/apache_kafka
- https://devops.profitbricks.com/tutorials/install-and-configure-apache-kafka-on-ubuntu-1604-1/
2 thoughts on “A Beginners Approach To “KAFKA”8 min read”
Comments are closed.