


Machines, working on our commands, for each step, they need guidance where to go what to do. This pattern is like a child who doesn’t understand the surrounding facts to make decisions for a situation. The grown ups usually do it for children. Same goes for machines. The developer writes the commands for the machine to be executed. But here in Machine Learning, we talk about making the machine learn which will enable the functionality of making decisions without any external help. That means a mature mind with the ability to understand facts and situations and choosing the right action for it.
To know the machine learning in a little more deeper I’d suggest you go through this introductory blog for Machine Learning.
In our previous blogs, we learned about Decision Tree algorithm (Link) for and its implementation (Link). Now in this blog, we will move on to the next algorithm for Machine Learning called Random Forest. Please go through these blogs before moving forward as Random Forest algorithm is based on Decision tree.
What is Random Forest
‘Another algorithm for Machine Learning‘ would be one liner for it, But as it’s been said by scholars, explaining things is necessary at each step in the process of knowledge sharing. So let’s go deeper in this algorithm.
‘Random Forest‘ as the name suggests is a forest and forest consists of trees. Here the trees being mentioned are Decision Trees. So the full definition will be “Random Forest is a random collection of Decision Trees”. Hence this algorithm is basically just an extension of Decision Tree algorithm.
Under The Hood
In this algorithm, we create multiple decision trees to the full extent (???). Yes, here we do not need to prune our decision trees. There is no such limitation for the trees in Random Forest. The catch here is that we don’t provide all the data for each decision tree to consume. We provide a random subset of our training data to each decision tree. This process is called Bagging or Bootstrap Aggregating.
Bagging is a general procedure that can be used to reduce the variance for those algorithms that have high variance. In this process, sub-samples are created for the data set and a subset of attributes, that we use to train our decision models and then we consider every model and choose the decision by voting -(classification) or by taking the average (regression). For the random forest, we usually take two third of the data with replacement (data can be repeated for every other decision tree, no need to be unique data). And the subset of the attributes m
In Random Forest each decision tree predicts a response for an instance. And the final response is decided based on voting. That means (in classification) the response which is received by the majority of decision trees becomes the final response. (In regression the average of all the responses becomes the final response).
Advantages
- Works better for both classification and regression.
- can handle large data set with a large number of attributes as these are divided among trees.
- It can model the importance of attributes. Hence it is used for dimensionality reduction also.
- Works well while maintaining accuracy even when data is missing
- It also works for unlabeled data (unsupervised learning) for clustering, data views and outlier detection.
- Random Forest uses the sampling of input data called as bootstrap sampling. In this one-third of the data is not used for training but for testing. These samples are called out of bag samples. And error regarding these is call out of bag error.
Out of Bag Error shows more or less the same error rate as a separate data set for training shows. Hence it removes the need of a separate test data set.
Disadvantages
- Classification is good with Random Forest but Regression…Not so much.
- Works as a black box. One can not control the inside functionality other than changing the input values etc.
Implementation
Now it’s time to see the implementation of Random Forest algorithm in Scala. Here we are gonna use Smile library to use Random Forest like we did for the implementation of Decision Trees
To use smile include the following dependency in your sbt project
libraryDependencies += "com.github.haifengl" %% "smile-scala" % "1.4.0"
We are going to use the same data for this implementation as we did for Decision Tree. Hence we get here Array of Array of Double as the training instances and Array of Int as response value for these instances.
val weather: AttributeDataset = read.arff("src/main/resources/weather.nominal.arff", 4) val (trainingInstances,responseVariables) = data.pimpDataset(weather).unzipInt
Training
After getting the data we have a method randomForest() in the package smile.operators package that returns an instance of RandomForest class.
val nTrees = 200 val maxNodes = 4
val rf = randomForest(trainingInstances, responseVariables, weather.attributes(), nTrees, maxNodes)
Here the parameters list for this method
- trainingInstances: Array[Array[Double]] *required
- responseVariables: Array[Int] – response values for each instance *required
- attributes: Array[Attribute] – an array of all the attributes (Attribute is class implemented in Java), by default this array is null.
- nodeSize: Int – the number of instances in a node below which the tree will not split, by default the value is 1 but for very large data set it should be more than one
- ntrees: Int – limits the number of trees, by default 500.
- maxNodes: Int – maximum number of leaf nodes in each decision tree (i.e total number of paths), by default its value is number of attributes / nodeSize
- mtry: Int – the number of randomly selected attributes for each decision tree, by default its value is the square root(number of attributes).
- subsample: Double – if the value is 1.0 then sampling with replacement if less than 1.0 then without replacement, by default the value is 1.0.
- splitRule: DecisionTree.SplitRule – the method on which the information gain is calculated for decision trees, could be GINI, ENTROPY, by default GINI.
- classWeight: Array[Int] – the ratio of the number of instances each class contains, if provided nothing, the algorithm calculates this value itself.
Testing
Now our Random Forest is created. We can use its error() method to show the out of bag error for our Random Forest.
println(s"OOB error = ${rf.error}")
The output is

Here we can see that the error in our random forest is 0.0 which is based on out of bag error. So we do not need to test it again with another dataset just for testing purposes.
Now we can use predict() method of RandomForest class to predict the outcome of some instance.
Accuracy
Our Random Forest is ready and we also checked the out of bag error. Now we know with every prediction we have some error also. So how to check the accuracy for the random forest we just built.
Voila!! we got the smile.validation package. In this package, we get many methods to test our models. Here we are taking one such method test(). It is a curried function and takes several parameters.
val testedRF = test(trainingInstances, responseVariables, testInstances, testResponseVariables)((_, _) => rf)
The parameter list is below
- trainingInstances: Array[Array[Double]]
- responseValues: Array[Int]
- testInstances: Array[Array[Double]]
- testResponseValues: Array[Int]
- trainer: anonymous method which takes trainingInstances and responseValues and returns a classifier
Here the testInstances and testResponseVaues are fetched from a testing data set. Shown below:
val weatherTest = read.arff("src/main/resources/weatherRF.nominal.arff", 4) val (testInstances,testResponseValues) = data.pimpDataset(weatherTest).unzipInt
Here is the output:
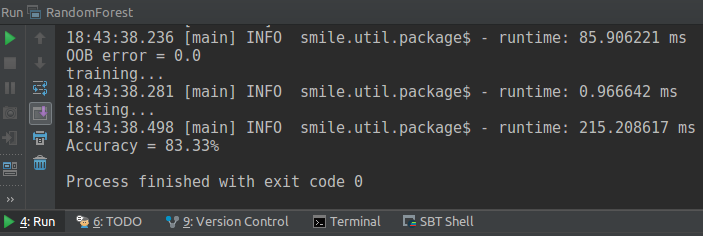
As we can see here it tells the accuracy for our random forest which is 83.33% right now.
This was all for Random Forest, a quick introduction and an implementation. Thanks.
The link to the sample code is here.
#mlforscalalovers
References:
{kind=link}

Very great blog on machine learning helped me a lot looking forward for some other blogs on this topic thanks again for such a great blog.
Reblogged this on Coding, Unix & Other Hackeresque Things.