

In this Blog we will be reading about Hadoop Map Reduce. As we all know to perform faster processing we needs to process the data in parallel. Thats Hadoop MapReduce Provides us.
MapReduce :- MapReduce is a programming model for data processing. MapReduce programs are inherently parallel, thus putting very large-scale data analysis into the hands of anyone with enough machines at their disposal.MapReduce works by breaking the processing into two phases:
- The map phase and,
- The reduce phase
Each phase has key-value pairs as input and output, the types of which may be chosen by the programmer. The programmer also specifies two functions:
- The map function and,
- The reduce function
The Map Function :- The key is the offset of the beginning of the line from the beginning of the file. Map function setting up the data in such a way that the reduce function can do its work on it. The map function is also a good place to drop bad records. so, generally we filter out the necessary data that we needs to process. To provide the body of Map Function we needs to extend Mapper class. To understand Map Function better lets take an example
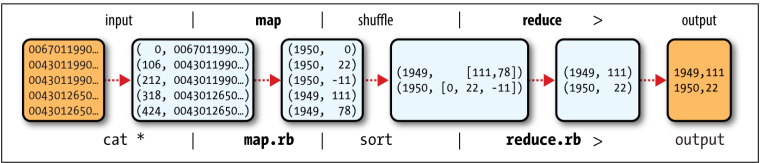
Example :- For example we are considering NCDC raw Data here is the sample
data. we need to find maximum temperature for each year.
0067011990999991950051507004…9999999N9+0000+99999999999…
0043011990999991950051512004…9999999N9+0022+199999999999…
0043011990999991950051518004…9999999N9-0011+99999999999…
0043012650999991949032412004…0500001N9+0111+99999999999…
0043012650999991949032418004…0500001N9+0078+99999999999…
So The Input for out Map Function is Something like this.
(0, 0067011990999991950051507004…9999999N9+000099999999999…)
(106, 0043011990999991950051512004…9999999N9+0022+99999999999…)
(212, 0043011990999991950051518004…9999999N9-0011+99999999999…)
(318, 0043012650999991949032412004…0500001N9+0111+99999999999…)
(424, 0043012650999991949032418004…0500001N9+0078+99999999999…)
The keys are the line offsets within the file, which we ignore in our map function. The
map function merely extracts the year and the air temperature (indicated in bold text),
and emits them as its output (the temperature values have been interpreted as
integers):
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
Code For Map Function :-
The Mapper class is a generic type, with four formal type parameters that specify the
input key, input value, output key, and output value types of the map function. For the
present example, the input key is a long integer offset, the input value is a line of text,
the output key is a year, and the output value is an air temperature (an integer). The map() method also provides an instance of Context to write the output to. In this case, we write the year as a Text object.
The Reduce Function :- In Reduce Function we perform actual computation. The operation that we needs to perform is totally depends on the user’s user case. The Input for the Reduce function is like this (Key, List( values) ).
Example Continue :- Here Input for the Reduce Function function is something like that
(1949, [111, 78])
(1950, [0, 22, −11])
now we Needs to find maximum temperature for each year.
Code For Reduce Function :-
Again four formal type parameters are used to specify the input and output types, this
time for the reduce function. The input types of the reduce function must match the
output types of the map function.
The output of our program is something like this.
(1949, 111)
(1950, 22)
The whole process of Hadoop map reduce can be seen in the following diagram.
This is a main Class from where you run the code.
A Job object forms the specification of the job and gives you control over how the job
is run. When we run this job on a Hadoop cluster, we will package the code into a JAR
file (which Hadoop will distribute around the cluster). Rather than explicitly specifying
the name of the JAR file, we can pass a class in the Job’s setJarByClass() method,
which Hadoop will use to locate the relevant JAR file by looking for the JAR file con‐
taining this class.
An input path is specified by calling the static addInputPath() method on FileInputFormat, and it can be a single file, a directory (in which case, the input forms all the files in that directory), or a file pattern.
The output path (of which there is only one) is specified by the static setOutput
Path() method on FileOutputFormat. It specifies a directory where the output files
from the reduce function are written. The directory shouldn’t exist before running the
job because Hadoop will complain and not run the job. This precaution is to prevent
data loss.
Next, we specify the map and reduce types to use via the setMapperClass() and
setReducerClass() methods. The setOutputKeyClass() and setOutputValueClass() methods control the output types for the reduce function, and must match what the Reduce class produces.
REFERENCE :- Hadoop The Definitive Guide 4th Edition
