

In our previous blog, MachineX: Layman guide to Association Rule Learning, we discussed what Association rule learning is all about. And as you can already tell, with a large dataset, which almost every market has, finding association rules isn’t very easy. For these, purposes, we introduced measures of interestingness, which were support, confidence and lift. Support tells us how frequent an itemset is in a given dataset and confidence tells us about the reliability of that rule. Due to large datasets, it is computationally very expensive to find both support and confidence for it.
An initial step towards improving the performance of association rule mining algorithms is to decouple the support and confidence requirements. Let’s look at it more closely.
Suppose a dataset exists such as the one below –

For the itemset {Beer, Diapers, Milk}, following rules exist –
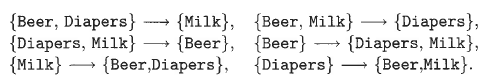
Support for all the above rules is identical since the rules involve items from the same itemset. Now, without any optimization, our next step would have been to calculate their confidence values. But, supposing this itemset to be infrequent, that is with a low support value, rules generated by this itemset cannot be of any interest to us. So, we don’t need to calculate the confidence to tell that we do not require these rules. So, just on the basis of its support, we can immediately prune all the rules generated by it. This, way we can achieve some degree of optimization.
For these purposes, association rule learning is divided into two parts –
- Frequent Itemset Generation
- Rule Generation
Frequent Itemset Generation
In this step, all the itemsets with support higher than the minimum support threshold are selected. This step gives us all the frequent itemsets in the dataset.
Rule Generation
In this step, high-confidence rules are extracted from the frequent itemsets that were obtained from the previous step. These rules are known as strong rules.
The computational requirements for frequent itemset generation are generally more expensive than those of rule generation.
In our next blog, we will be discussing about the apriori algorithm for frequent itemset generation and why is it not used much and it’s alternative. So stay tuned!
References –

Reblogged this on .