

Fan of Apache Spark? I am too. The reason is simple. Interesting APIs to work with, fast and distributed processing, unlike map-reduce no I/O overhead, fault tolerance and many more. With this much, you can do a lot in this world of Big data and Fast data. From “processing huge chunks of data” to “working on streaming data”, Spark works flawlessly in all. In this blog, we will be talking about the streaming power we get from Spark.
Spark provides us with two ways to work with streaming data
- Spark Streaming
- Structured Streaming (Since Spark 2.x)
Let’s discuss what are these exactly, what are the differences and which one is better.
Spark Streaming
Spark Streaming is a separate library in Spark to process continuously flowing streaming data. It provides us the DStream API which is powered by Spark RDDs. DStreams provide us data divided in chunks as RDDs received from the source of Streaming to be processed and after processing sends it to the destination. Cool right!
Structured Streaming
Spark 2.x release onwards, Structured Streaming came into the picture. Built on Spark SQL library, Structures Streaming is another way to handle streaming with Spark. This model of streaming is based on Dataframe and Dataset APIs. Hence with this library, we can easily apply any SQL query (using DataFrame API) or scala operations (using DataSet API) on streaming data.
Okay, so that was the summarized theory for both ways of streaming in Spark. Now we need to know where one triumphs another.
Distinctions
1. Real Streaming
What does real streaming imply? Data which is unbounded and is being processed upon receiving from the Source. This definition is satisfiable (more or less).
If we talk about Spark Streaming, this is not the case. Spark streaming works on something which we call a micro batch. The stream pipeline is registered with some operations and the Spark polls the source after every batch duration (defined in the application) and then a batch is created of the received data. i.e. each incoming record belongs to a batch of DStream. Each batch represents an RDD.
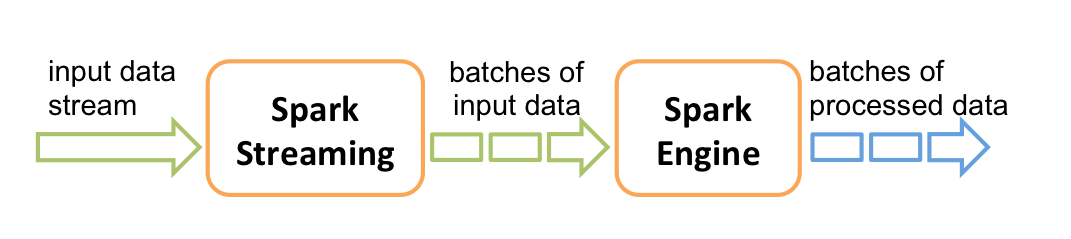
Structured Streaming works on the same architecture of polling the data after some duration, based on your trigger interval but it has some distinction from the Spark Streaming which makes it more inclined towards real streaming. In Structured streaming, there is no concept of a batch. The received data in a trigger is appended to the continuously flowing data stream. Each row of the data stream is processed and the result is updated into the unbounded result table. How you want your result (updated, new result only or all the results) depends on the mode of your operations (Complete, Update, Append).

Winner of this round: Structured Streaming.
2. RDD v/s DataFrames|DataSet

Another distinction can be the use case of different APIs in both streaming models. In summary, we read that the Spark Streaming works on DStream API which is internally using RDDs and Structured Streaming uses Dataframe and Dataset APIs to perform streaming operations. So it is a straight comparison between using RDDs or DataFrames. There are several blogs available which compare DataFrames and RDDs in terms of `performance` and `ease of use`. A good read for RDD v/s Dataframes. All those comparisons lead to one result that DataFrames are more optimized in terms of processing and provides more options of aggregations and other operations with a variety of functions available (many more functions are now supported natively in Spark 2.4).
So Structured streaming wins here with flying colors.
3. Processing with the event time, Handling late data

One great issue in the streaming world is to process data according to the event-time. Event-time is the time when the event actually happened. It is not necessary that the source of the streaming engine is proving data in exactly real time. There may be latencies in data generation and handing over the data to the processing engine. There is no such option in Spark Streaming to work on the data using the event-time. It only works with the timestamp when the data is received by the Spark. Based on the ingestion timestamp the Spark streaming put the data in a batch even if the event is generated early and belonged to the earlier batch which may result in less accurate information as it is equal to the data loss. On the other hand, Structured streaming provides the functionality to process the data on the basis of event-time when the timestamp of the event is included in the data received. This is a major feature introduced in Structured streaming which provides a different way of processing the data according to the time of data generation in the real world. With this, we can handle late coming data and get more accurate results.
With the event-time handling of late data feature, Structure Streaming outweighs Spark Streaming.
4. End to end guarantees

Every application requires one thing with utmost priority which is: Fault tolerance and End to End guarantee of delivering the data. Whenever the application fails it must be able to restart from the same point when it failed to avoid data loss and duplication. To provide fault tolerance Spark Streaming and Structured streaming, both use the checkpointing to save the progress of a job. But this approach still has many holes which may cause data loss.
Other than checkpointing, Structured streaming has applied two conditions to recover from any error:
- The source must be replayable
- The Sinks must support idempotent operations to support reprocessing in case of failures.
To know more
With restricted sinks, the Spark Structured Streaming always provides End to End EXACTLY ONCE semantics. Way to go Structured Streaming 🙂
5. Restricted or Flexible:

Sink: The destination of a streaming operation. It can be external storage, a simple output to console or any action.
With Spark Streaming there is no restriction to use any type of sink. Here we have the method foreachRDD` to perform some action on the stream. This method returns us the RDDs created by each batch one by one and we can perform any actions over them like saving to any storage, performing some computations and anything we can think of. We can cache an RDD and perform multiple actions on it as well (even sending to multiple databases as well).
But in Structures Streaming till v2.3, we had a limited number of output sinks and with one sink only one operation can be performed and we can not save the output at multiple external storages. To use a custom sink, the user needed to implement `ForeachWriter`. But here comes the Spark 2.4 and with this version, we have a new sink called `foreachBatch` which gives us the resultant output table as a Dataframe and hence we can use this Dataframe to perform our custom operations.
With this new sink, the `restricted` Structured Streaming is now more `flexible` and gives now an edge over the Spark Streaming over flexible sinks as well.
Conclusion
We saw a fair comparison between Spark Streaming and Spark Structured Streaming above on basis of few points. We can clearly say that Structured Streaming is more inclined towards real-time streaming but Spark Streaming focuses more on batch processing. The APIs are better and optimized in Structured Streaming where Spark Streaming is still based on the old RDDs.
So to conclude this blog we can simply say that Structured Streaming is a better Streaming platform in comparison to Spark Streaming.
Please make sure to comment your thoughts on this 🙂
References:
