

Hello Folks, In this blog i will explain twitter’s tweets analysis with lambda architecture. So first we need to understand what is lambda architecture,about its component and usage.
According to Wikipedia, Lambda architecture is a data processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream processing methods.
Now let us see lambda architecture components and its detail.
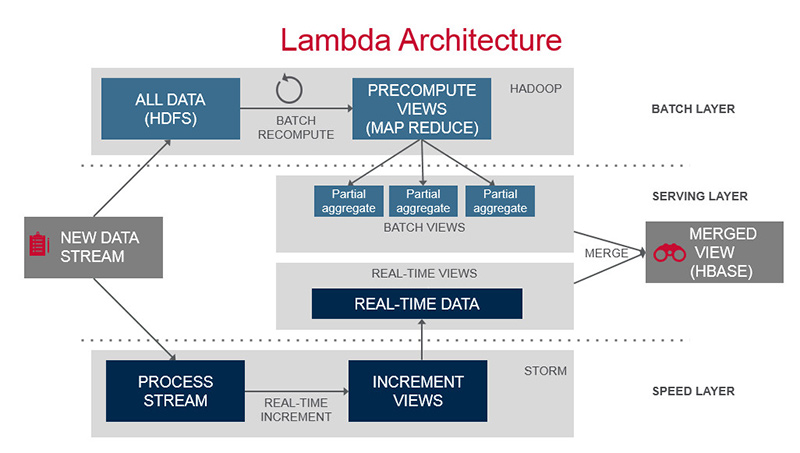
This architecture is classified into three layer :
Batch Layer : The batch layer precomputes the master dataset(it is core components of lambda architecture and it contains all data) into batch views so that queries can be resolved with low latency.
Speed Layer: In speed layer we are basically do two things,storing the realtime views and processing the incoming data stream so as to update those views.It fills the delta gap that is left by batch layer.that means combine speed layer view and batch view give us capability fire any adhoc query over all data that is query=function(over all data).
Serving Layer: It provides low-latency access to the results of calculations performed on the master dataset . It combines batch view and realtime view to give result in realtime for any adhoc query over all data.
So in short we can say lambda architecture is query=function(over all data).
Now i am going to describe twitter’s tweet analysis with the help of lambda architecture.This project uses twitter4j streaming api and Apache Kafka to get and store twitter’s realtime data.I have used Apache Cassandra for storing Master dataset ,batch view and realtime view.
Batch Layer of project : To process data in batch we have used Apache Spark (fast and general engine for large-scale data processing) engine and to store batch view we have used cassandra. To do this we have created BatchProcessingUnit to create all batch view on master dataset.
class BatchProcessingUnit {
val sparkConf = new SparkConf()
.setAppName("Lambda_Batch_Processor").setMaster("local[2]")
.set("spark.cassandra.connection.host", "127.0.0.1")
.set("spark.cassandra.auth.username", "cassandra")
val sc = new SparkContext(sparkConf)
def start: Unit ={
val rdd = sc.cassandraTable("master_dataset", "tweets")
val result = rdd.select("userid","createdat","friendscount").where("friendsCount > ?", 500)
result.saveToCassandra("batch_view","friendcountview",SomeColumns("userid","createdat","friendscount"))
result.foreach(println)
}
}
We have used Akka scheduler to schedule batch process in specified interval.
Speed Layer of project: In speed layer we have used Spark Streaming to process realtime tweets and store its view in cassandra.
To do this we have created SparkStreamingKafkaConsumer which read data from kafka queue “tweets” topic and send to view handler of speed layer to generate all view.
object SparkStreamingKafkaConsumer extends App {
val brokers = "localhost:9092"
val sparkConf = new SparkConf().setAppName("KafkaDirectStreaming").setMaster("local[2]")
.set("spark.cassandra.connection.host", "127.0.0.1")
.set("spark.cassandra.auth.username", "cassandra")
val ssc = new StreamingContext(sparkConf, Seconds(10))
ssc.checkpoint("checkpointDir")
val topicsSet = Set("tweets")
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers, "group.id" -> "spark_streaming")
val messages: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val tweets: DStream[String] = messages.map { case (key, message) => message }
ViewHandler.createAllView(ssc.sparkContext, tweets)
ssc.start()
ssc.awaitTermination()
}
Serving Layer of Project: In serving layer basically we have combined batch view data and realtime view data to satisfy adhoc query requirement.Here is an example in which have try to analyse all twitter users who match the specify hashtag and they have follower counts greater than 500 .
def findTwitterUsers(minute: Long, second: Long, tableName: String = "tweets"): Response = {
val batchInterval = System.currentTimeMillis() - minute * 60 * 1000
val realTimeInterval = System.currentTimeMillis() - second * 1000
val batchViewResult = cassandraConn.execute(s"select * from batch_view.friendcountview where createdat >= ${batchInterval} allow filtering;").all().toList
val realTimeViewResult = cassandraConn.execute(s"select * from realtime_view.friendcountview where createdat >= ${realTimeInterval} allow filtering;").all().toList
val twitterUsers: ListBuffer[TwitterUser] = ListBuffer()
batchViewResult.map { row =>
twitterUsers += TwitterUser(row.getLong("userid"), new Date(row.getLong("createdat")), row.getLong("friendscount"))
}
realTimeViewResult.map { row =>
twitterUsers += TwitterUser(row.getLong("userid"), new Date(row.getLong("createdat")), row.getLong("friendscount"))
}
Response(twitterUsers.length, twitterUsers.toList)
}
Finally this project used Akka HTTP for build rest api to fire adhoc queries.
I hope, it will be helpful for you in building Big data application using lambda architecture.
You can get source code here
References:
https://en.wikipedia.org/wiki/Lambda_architecture
http://lambda-architecture.net/
https://www.mapr.com/developercentral/lambda-architecture

Reblogged this on imsonublog.
Reblogged this on Dhirendra.
Reblogged this on bigtechnologies.
Reblogged this on Anurag Srivastava.
Reblogged this on prashantgoel6.
Very nicely explained…
Hello Narayan, we are trying to run the example. We went to the github location, got the source code and followed all the steps. At the sbt clean compile step, we are getting an exception and that’s where we are being stuck. We’ll appreciate your help in resolving this.
The relevant portion of my console log is reproduced below – My guess is that although we specified scala 2.11, it is taking scala 2.12 by default and checking an incorrect path. But I am not sure how to get it right.
[warn] ==== bintray-spark-packages: tried
[warn] https://dl.bintray.com/spark-packages/maven/org/spark-packages/sbt-spark-package_2.12_1.0/0.2.5/sbt-spark-package-0.2.5.pom
[info] downloading https://repo1.maven.org/maven2/org/apache/logging/log4j/log4j-core/2.8.1/log4j-core-2.8.1-tests.jar …
[info] [SUCCESSFUL ] org.apache.logging.log4j#log4j-core;2.8.1!log4j-core.jar(test-jar) (7268ms)
[warn] ::::::::::::::::::::::::::::::::::::::::::::::
[warn] :: UNRESOLVED DEPENDENCIES ::
[warn] ::::::::::::::::::::::::::::::::::::::::::::::
[warn] :: org.spark-packages#sbt-spark-package;0.2.5: not found
[warn] ::::::::::::::::::::::::::::::::::::::::::::::
[warn]
[warn] Note: Some unresolved dependencies have extra attributes. Check that these dependencies exist with the requested attributes.
[warn] org.spark-packages:sbt-spark-package:0.2.5 (scalaVersion=2.12, sbtVersion=1.0)
[warn]
[warn] Note: Unresolved dependencies path:
[warn] org.spark-packages:sbt-spark-package:0.2.5 (scalaVersion=2.12, sbtVersion=1.0) (/home/ab/tmp2/Lambda-Arch-Spark-master/project/plugins.sbt#L3-4)
[warn] +- default:lambda-arch-spark-master-build:0.1-SNAPSHOT (scalaVersion=2.12, sbtVersion=1.0)
[error] sbt.librarymanagement.ResolveException: unresolved dependency: org.spark-packages#sbt-spark-package;0.2.5: not found
[error] at sbt.internal.librarymanagement.IvyActions$.resolveAndRetrieve(IvyActions.scala:331)
[error] at sbt.internal.librarymanagement.IvyActions$.$anonfun$updateEither$1(IvyActions.scala:205)
[error] at sbt.internal.librarymanagement.IvySbt$Module.$anonfun$withModule$1(Ivy.scala:229)
Hi @Ashish B. Did you managed to get it work? I have the same issue here.
Thanks for reply.
Plz help me ! i could not run SparkStreamingKafkaConsumer and i got NoClassDefFoundError, this is my question on SO https://stackoverflow.com/questions/50259084/scala-java-lang-noclassdeffounderror
Thanks in advance