


Spark 2.0 is the next major release of Apache Spark. This brings major change for the level of abstraction for the spark API and libraries. The release has the major change for the ones who want to make use of all the advancement in this release, So in this blog post, I’ll be discussing Spark-Session.
Need Of Spark-Session
Before understanding spark-session let’s understand the entry-point, An entry-point is where control is transferred from the operating system to the provided program. Before 2.0 entry-point to spark-core was the sparkContext.Apache Spark is a powerful cluster computing engine, therefore it is designed for fast computation of big data.
SparkContext in Apache Spark:

This is the important step of any spark driver application is to generate SparkContext. It allows your spark-application to access Spark cluster with the help of Resource manager. The resource manager can be one of these three :
- SparkStandalone
- YARN
- Apache
- Mesos
Functions of SparkContext in Apache Spark:
- Get the current status of spark application
- Set configurations
- Access various service
- Cancel a job
- Cancel a stage
- Closure cleaning
- Register Spark-Listener
- Programmable Dynamic allocation
- Access persistent RDD
Prior to spark 2.0, SparkContext was used as a channel to access all spark functionality. The spark driver program uses sparkContext to connect to the cluster through resource manager.
SparkConf is required to create the spark context object, which stores configuration parameters like appName (to identify your spark driver), number core and memory size of executor running on worker node.
In order to use API’s of SQL, Hive, and Streaming, separate context needs to be created.
Example:
val conf = new SparkConf() .setMaster("local") .setAppName("Spark Practice") val sc = new SparkContext(conf)
SparkSession – New entry-point of Spark

As we know, in previous versions, spark context is the entry point for spark, As RDD was the main API, it was created and manipulated using context API’s. For every other API, we needed to use a different context.
For streaming we needed streamingContext. For SQL sqlContext and for hive hiveContext.But as dataSet and DataFrame API’s are becoming new standalone API’s we need an entry-point build for them. So in spark 2.0, we have a new entry point build for DataSet and DataFrame API’s called as Spark-Session.

Its a combination of SQLContext, HiveContext and future streamingContext. All the API’s available on those contexts are available on SparkSession also SparkSession has a spark context for actual computation.
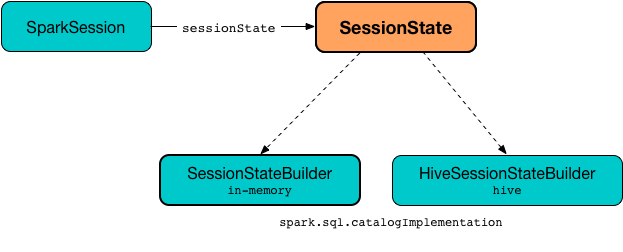
Now we can forward how to create Spark Session and intersect with it.
Creating a Spark Session
Following codes are come in handy when you want to create SparkSession :
val spark = SparkSession.builder() .master("local") .appName("example of SparkSession") .config("spark.some.config.option", "some-value") .getOrCreate()
SparkSession.builder()
This method is created for constructing a SparkSession.
master(“local”)
Sets the spark master URL to connect to such as :
- “local” to run locally
- “local[4]” to run locally with 4 cores
- “spark://master:7077” to run on a spark standalone cluster
appName( )
Set a name for the application which will be shown in the spark Web UI.
If no application name is set, a randomly generated name will be used.
Config
Sets a config option set using this method are automatically propagated to both ‘SparkConf’
and ‘SparkSession’ own configuration, its arguments consist of key-value pair.
GetOrElse
Gets an existing SparkSession or, if there is a valid thread-local SparkSession and if yes, return that one. It then checks whether there is a valid global default SparkSession and if yes returns that one. If no valid global SparkSession exists, the method creates a new SparkSession and assign newly created SparkSession as the global default.
In case an existing SparkSession is returned, the config option specified in this builder will be applied to existing SparkSession
The above is similar to creating a SparkContext with local and creating an SQLContext wrapping it. If you can need to create hive context you can use below code to create spark session with hive support:
val spark = SparkSession.builder() .master("local") .master("local") .appName("example of SparkSession") .config("spark.some.config.option", "some-value") .enableHiveSupport() .getOrCreate()
enableHiveSupport on factory enable Hive support which is similar to HiveContext
one created sparkSession, we can use it to read the data.
Read data Using SparkSession
SparkSession is the entry point for reading data, similar to the old SQLContext.read.
The below code is reading data from CSV using SparkSession :
val df = spark.read.format("com.databricks.spark.csv") .schema(customSchema) .load("data.csv")
Spark 2.0.0 onwards, it is better to use SparkSession as it provides access to all the spark functionalities that sparkContext does. Also, it provides API to work on DataFrames and DataSets
Running SQL queries
SparkSession can be used to execute SQL queries over data, getting the result back as Data-Frame (i.e. Dataset[ROW]).
display(spark.sql("Select * from TimeStamp"))
+--------------------+-----------+----------+-----+
| TimeStamp|Temperature| date| Time|
+--------------------+-----------+----------+-----+
|2010-02-25T05:42:...| 79.48|2010-02-25|05:42|
|2010-02-25T05:42:...| 59.27|2010-02-25|05:42|
|2010-02-25T05:42:...| 97.98|2010-02-25|05:42|
|2010-02-25T05:42:...| 91.41|2010-02-25|05:42|
|2010-02-25T05:42:...| 60.67|2010-02-25|05:42|
|2010-02-25T05:42:...| 61.41|2010-02-25|05:42|
|2010-02-25T05:42:...| 93.6|2010-02-25|05:42|
|2010-02-25T05:42:...| 50.32|2010-02-25|05:42|
|2010-02-25T05:42:...| 64.69|2010-02-25|05:42|
|2010-02-25T05:42:...| 78.57|2010-02-25|05:42|
|2010-02-25T05:42:...| 66.89|2010-02-25|05:42|
|2010-02-25T05:42:...| 62.87|2010-02-25|05:42|
|2010-02-25T05:42:...| 74.32|2010-02-25|05:42|
|2010-02-25T05:42:...| 96.55|2010-02-25|05:42|
|2010-02-25T05:42:...| 71.93|2010-02-25|05:42|
|2010-02-25T05:42:...| 79.17|2010-02-25|05:42|
|2010-02-25T05:42:...| 73.89|2010-02-25|05:42|
|2010-02-25T05:42:...| 80.97|2010-02-25|05:42|
|2010-02-25T05:42:...| 81.04|2010-02-25|05:42|
|2010-02-25T05:42:...| 53.05|2010-02-25|05:42|
+--------------------+-----------+----------+-----+
only showing top 20 rows
Working with config Options
SparkSession can also be used to set runtime configuration options which can toggle optimizer behavior or I/O (i.e. Hadoop) behavior.
Spark.conf.get(“Spark.Some.config”,”abcd”)
Spark.conf.get(“Spark.Some.config”)
and config options set can also be used in SQL using variable substitution
%Sql select “${spark.some.config}”
Working with metadata directly
SparkSession also includes a catalog method that contains methods to work with the metastore (i.e. data catalog). Method return Datasets so you can use the same dataset API to play with them.
To get a list of tables in the current database
val tables =spark.catalog.listTables()
display(tables)
+----+--------+-----------+---------+-----------+ |name|database|description|tableType|isTemporary| +----+--------+-----------+---------+-----------+ |Stu |default |null |Managed |false | +----+--------+-----------+---------+-----------+
use the dataset API to filter on names
display(tables.filter(_.name contains “son”)))
+----+--------+-----------+---------+-----------+ |name|database|description|tableType|isTemporary| +----+--------+-----------+---------+-----------+ |Stu |default |null |Managed |false | +----+--------+-----------+---------+-----------+
Get the list of the column for a table
display(spark.catalog.listColumns(“smart”))
+-----+----------+----------+-----------+-------------+--------+ |name |description|dataType |nullable |isPartitioned|isbucket| +-----+-----------+---------+-----------+-------------+--------+ |email|null |string |true |false |false | +-----+-----------+---------+-----------+-------------+--------+ |iq |null |bigInt |true |false |false | +-----+-----------+---------+-----------+-------------+--------+
Access the underlying SparkContext
SparkSession.sparkContext returns the underlying sparkContext, used for creating RDDs as well as managing cluster resources.
Spark.sparkContext
res17: org.apache.spark.SparkContext = org.apache.spark.SparkContext@2debe9ac
You can check the complete code below :

Thanks for the blog post and specially the source code actually new to spark it helped for quick setup.
Hi, can I use our image (https://abhishekbaranwal10.files.wordpress.com/2018/09/introduction-to-apache-spark-20-12-638.jpg?resize=638%2C479)? It’s the best and the sorthest of sparkSession and sparkContext explanation i have ever found.
TK